AI Sales Intelligence Platform
Built a production-grade multi-step RAG system to process city-level healthcare distribution reports, distill them into ranked priority signals, and surface expansion recommendations through a role-based dashboard — helping regional teams decide where to push next.
Year
2024
Category
AI / RAG
Stack
FastAPI, LangChain, pgvector
Key Results
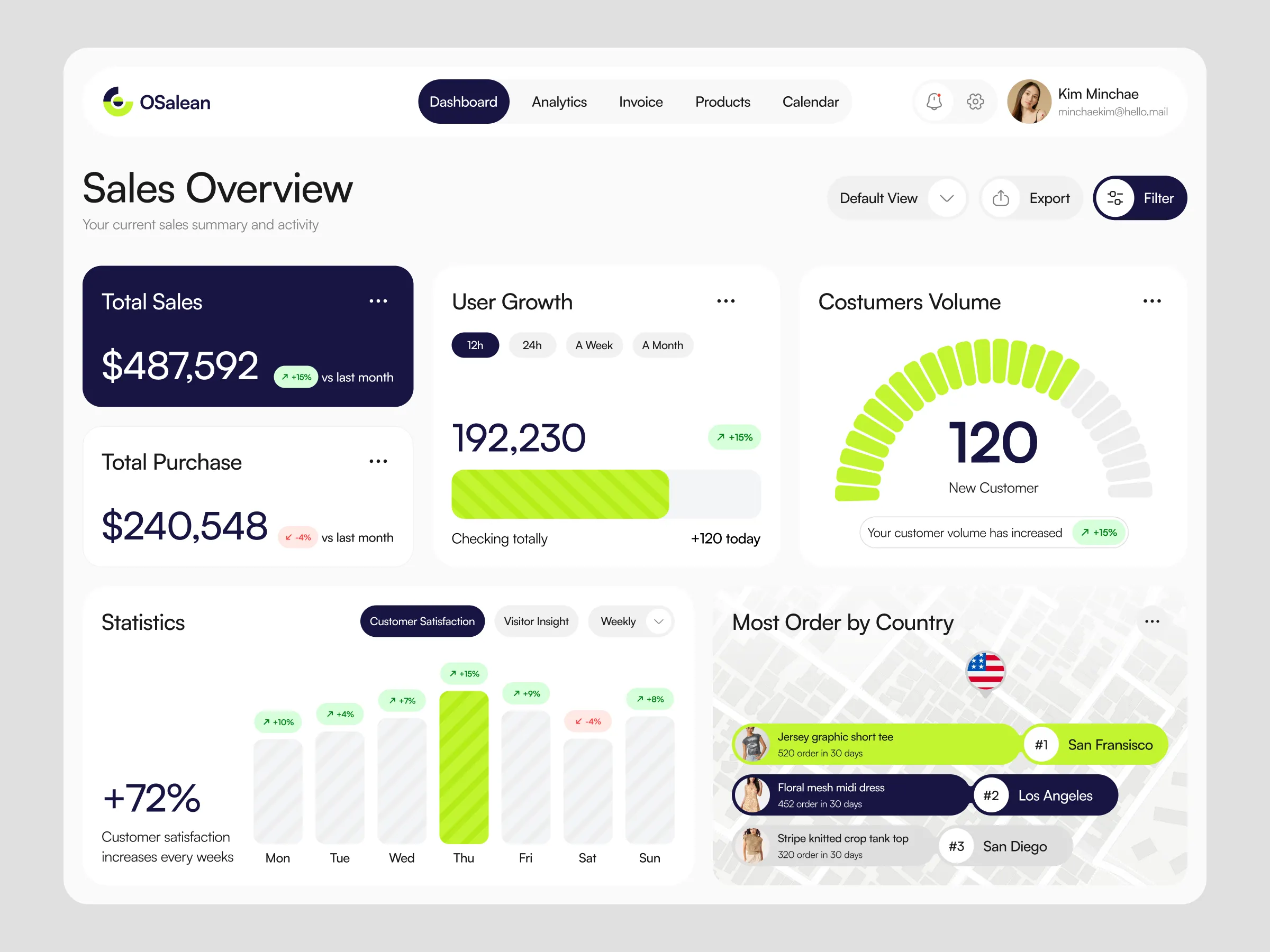
96%
Signal Accuracy
on benchmark set
8 min
Analysis Time
down from 3–4 hrs
500+
Daily Queries
at sub-2s latency
3×
Team Expansion
within 2 months
01
The Challenge
A mid-sized pharma distribution company was expanding into new cities across India. Their strategy team had commissioned hundreds of city-level market reports — hospital density, chemist network coverage, competitor presence, demographic data — all locked inside PDFs across shared drives. Regional managers were spending 3–4 hours per city manually reading through reports to judge whether to push distribution there. Leadership needed a system that could reason across all of it and tell the team which cities to prioritise — with a clear, auditable signal instead of a gut call.
02
What We Built
We built a multi-step RAG pipeline where city-level documents are chunked, embedded, and stored in pgvector. At query time we run a three-stage LangChain LCEL chain rather than a single LLM call: the first prompt extracts key market signals from retrieved chunks, the second reasons across those signals to produce a structured city assessment, and a final distillation prompt collapses everything into a 4-word priority label — 'Expand Now', 'High Potential', 'Needs Nurturing', or 'Deprioritise'. These labels populate a sortable priority table on the dashboard. Role-based auth ensures each company sees only their own city data, and regional leads can flag cities and assign them to field reps directly from the table.
03
Results
City analysis time dropped from 3–4 hours to under 8 minutes. The pipeline handles 500+ queries daily at sub-2s latency. Within two months the client rolled the dashboard out to three regional teams, replacing spreadsheet-based tracking entirely and giving leadership a live view of expansion priorities across 200+ cities.
04
Before & After
Before
Regional managers spent 3–4 hours per city reading PDFs to assess expansion potential
Hundreds of city reports were unsearchable across shared drives
Prioritisation depended on whoever had read the reports most recently
No audit trail — impossible to verify why a city was flagged as high priority
After
Each city analysed and labelled in under 8 minutes with a cited 4-word priority signal
Every report instantly queryable with sub-2s response times
Any team member can query the system independently, 24/7, with consistent output
Every label traces back to source citations with document and page references
05
How We Built It
We broke the build into four sequential phases, each with a clear deliverable before moving to the next.
Data audit & pipeline design
Catalogued all city reports, assessed quality and structure variance across different report formats, and designed the chunking strategy. Validated pgvector latency targets before committing to the stack.
Ingestion pipeline
Built the S3 upload flow, PyMuPDF text extraction, 512-token chunking with 64-token overlap, and the Celery worker that manages embedding jobs asynchronously across hundreds of documents.
Multi-step query chain
Implemented the three-stage LangChain LCEL chain — signal extraction, structured city reasoning, and 4-word priority distillation — with citation enforcement at every step so every label is traceable.
Next.js dashboard & role-based auth
Built the Next.js frontend with shadcn/ui and Tailwind CSS featuring a sortable priority table, SSE token streaming for city deep-dives, expandable citation chips, and role-based access so each company sees only their own regional data.
06
System Architecture
The system splits into two flows: an async ingestion pipeline and a synchronous multi-step query pipeline. Ingestion moves through S3, a Celery worker, and pgvector. Queries are synchronous FastAPI endpoints that run a three-stage LangChain chain and stream the final output back to the dashboard.
Ingestion Layer
S3 + Celery + PyMuPDF
City reports land in S3. A Celery worker extracts text with PyMuPDF, chunks into 512-token segments with 64-token overlap, and dispatches embedding jobs.
Embedding Service
OpenAI text-embedding-3-small
Each chunk is embedded via the OpenAI embeddings API. Embeddings are 1536-dimensional vectors stored with chunk metadata in pgvector.
Vector Store
PostgreSQL + pgvector
HNSW index on the embedding column enables approximate nearest-neighbour search at sub-50ms latency across millions of vectors.
Multi-Step Query Chain
FastAPI + LangChain LCEL
Three chained prompts run in sequence: (1) extract market signals from retrieved chunks, (2) reason across signals into a structured city assessment, (3) distil the assessment into a 4-word priority label with confidence score.
LLM Layer
OpenAI GPT-4o
Each prompt stage uses GPT-4o with a structured output schema. The final stage is constrained to four possible labels to eliminate hallucinated verdicts.
Frontend
Next.js + shadcn/ui + Tailwind CSS
Streams city assessment tokens via SSE. Renders the distilled priority label in a sortable table. Citation chips built with shadcn Badge and Popover expand to show the original document chunk each signal was drawn from.
07
Tech Stack
Backend
AI / ML
Database
Infrastructure
Frontend
08
How We Approached the Problem
Before writing code we mapped the full reasoning chain the system needed to replicate: what signals matter for a city, how those signals combine into a judgement, and what the final output needs to look like for a field rep to act on it immediately. We deliberately chose a three-stage chain over a single large prompt — each stage is independently testable and the intermediate outputs are logged, making it easy to debug where the chain goes wrong on edge-case cities.
Alternatives considered & rejected
Single-shot prompt for the full analysis
A single prompt asking for extraction, reasoning, and distillation in one pass produced inconsistent label quality. Breaking it into three stages with intermediate validation improved accuracy significantly.
Pinecone as vector store
Added an external dependency and egress cost. pgvector on the existing Postgres instance met p95 latency targets at a fraction of the price.
LlamaIndex instead of LangChain
LlamaIndex had better document loaders but weaker chain composition. LangChain LCEL made it easier to build testable, swappable pipeline steps across the three prompt stages.
09
Data Modelling
Three core tables: companies (RBAC anchor), documents (city report metadata per company), and document_chunks (text segments with embeddings). Keeping company_id on both documents and chunks means every similarity search is automatically scoped — no application-layer filtering needed.
10
API Layer
The query endpoint runs a three-stage LangChain LCEL chain. Each stage is a typed Runnable — independently testable and swappable. The final stage is constrained to four labels via an enum in the output schema, eliminating free-text hallucinations in the priority signal.
11
Database Functions
Similarity search is scoped to the calling company at the SQL level — not in application code. This means even if a bug bypasses the application auth layer, cross-company data leakage is structurally impossible.
12
Frontend Connection
A custom hook manages the SSE stream and assembles the three-stage chain output as it arrives. The priority table updates optimistically — the label renders as soon as the distillation stage streams back, without waiting for the full response to complete.
13
Lessons Learned
Single-shot prompts break on complex reasoning
Asking one prompt to extract signals, reason across them, and produce a label in one pass gave inconsistent results on edge-case cities. Breaking it into three stages with typed intermediate outputs fixed accuracy and made debugging trivial.
Constrain the final output to an enum
Leaving the priority label as free text produced creative variations like 'Expand Cautiously' that broke the frontend sort logic. Enforcing a Literal type in the Pydantic schema eliminated this entirely.
Scope at the database level, not just the application
Putting company_id filtering inside a SQL function means cross-company data leakage is structurally impossible — not just dependent on application code being correct.
Stream intermediate stages, not just the final answer
Showing 'Extracting signals... Assessing city... Distilling priority...' as each stage completed made a 6-second chain feel fast. A blank screen for the same duration felt broken.
Start a project